eDNA Historian¶
The flir-north-edna plugin is designed to send data from FLIR Bridge to the AVEVA eDNA historian. The plugin can operate in two modes; it can either create new points within eDNA or it can use points that have already been created.
The process for creating an eDNA pipeline to send data from FLIR Bridge is similar to any other north setup
Selecting the North option in the left-hand menu bar
Click on the add icon in the top right corner.
In the North Plugin list select the eDNA option.
Click Next
Configure your eDNA plugin
Click Next
Enable your north task and click on Done
Configuration¶
The configuration of the plugin is divided into a number of tabs within the configuration page, each of these tabs is documented below.
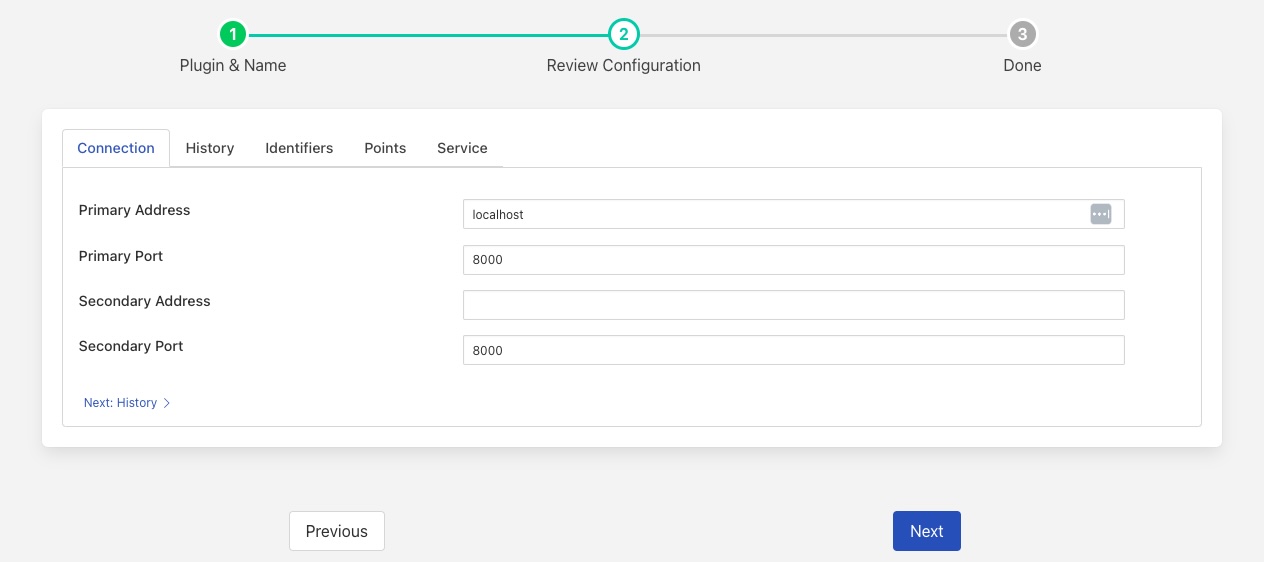
Connection¶
The Connection tab allows you to define a primary and secondary server to connect to.
Primary Address: The address of the primary eDNA server to which to connect.
Primary Port: The port the input listening of your eDNA service is using on the primary server.
Secondary Address: The address of the primary eDNA server to which to connect.
Secondary Port: The port the input listening of your eDNA service is using on the primary server.
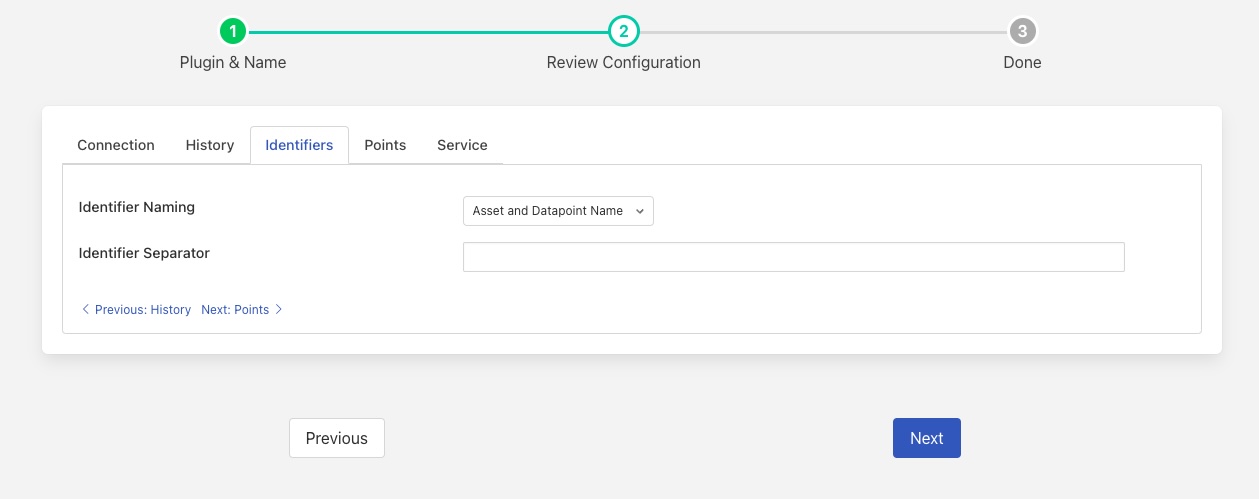
Identifiers¶
The Identifiers tab controls how eDNA identifiers are created by FLIR Bridge when it creates new points in eDNA. All three identifiers are created and use the same value. If the short identifiers is greater than 8 characters then eDNA will truncate the generated identifier to 8 characters.
Identifier Naming: This controls which components are used when creating an identifier for the data point in eDNA. The user can configure to use just the asset name, just the data point name or a concatenation of both the asset name and data point name. See eDNA Identifiers.
Identifier Separator: A string to use to separate the asset name and data point name if using both to form a unique identifier.
Note
If an eDNA hint is included, using the eDNA Hint filter, within the reading and that hint sets any one or all of the identifiers for a datapoint within the reading, then the hint values will override the values derived from the settings above.
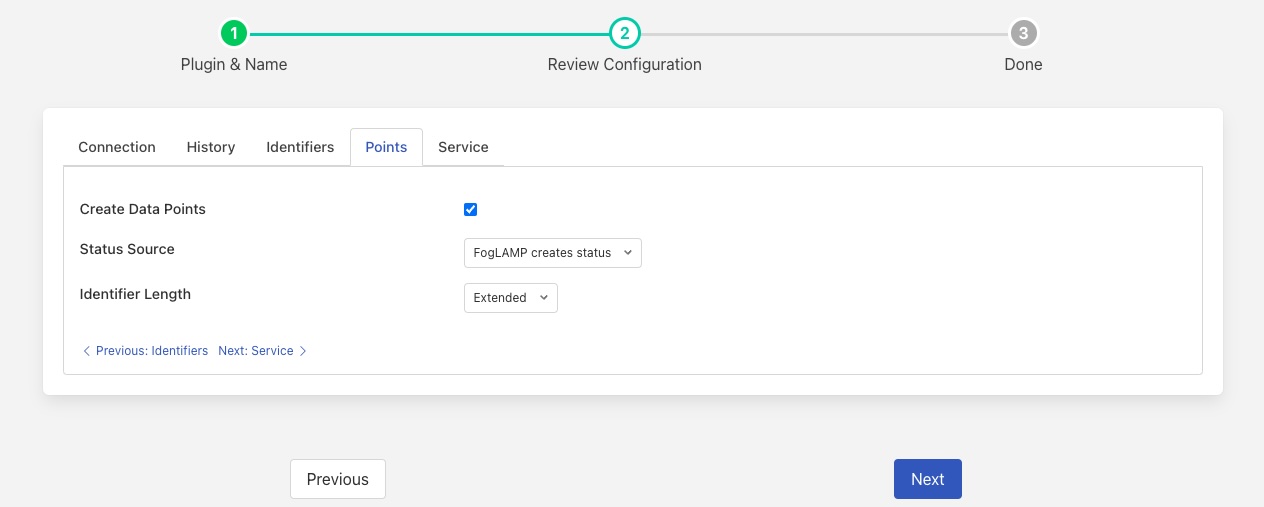
Points¶
Create Data Points: A toggle to control if FLIR Bridge should create new data points within eDNA if it it should use existing data points. This is the toggle between the two modes of operation of the plugin. When disabled the identifiers created by the plugin must match the eDNA point names, see Matching Predefined Points for more details.
Status Source: The source of the status associated with the data points. This may be either FLIR Bridge itself or it may be determined by eDNA by using the rule set within eDNA.
Identifier Length: The length of identifiers to use when adding data to the points within eDNA. This may be one of short or long identifiers.
Note
Setting the identifier length merely controls which identifier is used when adding data to points. The points will be created with a short, long and extended identifier. The identifiers are created either using the eDNA hint associated with the reading or the algorithm set in the Identifiers tab.
It is currently not possible to insert data using extended identifiers, however the extended identifiers are added to the points when created and the data can be queried using extended identifiers.
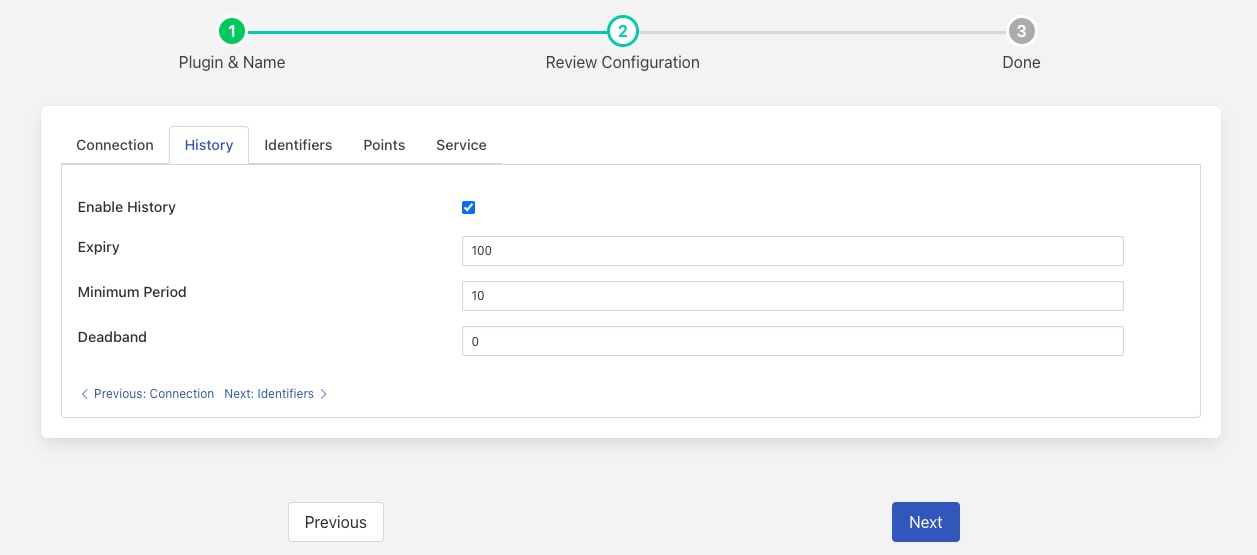
History¶
The history tab is only used when FLIR Bridge creates data points within eDNA, it defines the default set of parameters that will be set for sending the data to the history.
Enable History: Enable sending newly created points in eDNA to history.
Expiry: Number of days a history value is retained.
Minimum Period: Period, in seconds, indicating the minimum time period between which points are logged to history. If a point updates more often than the minimum period, the point is not sent to history until that minimum period elapses.
Deadband: Deadband used in the store-on-change algorithm, changed of less than the deadband value are not sent to the history. A value of zero logs every change.
The history settings for individual eDNA points created can be overridden using the eDNA Hint mechanism.
eDNA Identifiers¶
In either of the two modes of operation, with FLIR Bridge creating points or if reusing points within the eDNA server, it is important to understand how FLIR Bridge will create the point identifiers. It is important to understand the FLIR Bridge naming structure for data. FLIR Bridge has a concept of asset, which have a name and within the assets a number of datapoints that are the actual values for that asset. Asset names must be unique within a FLIR Bridge instance, datapoint names must be unique within a given asset, but can be the same name as datapoints within a different asset.
As an example you may have two assets that represent a cooling tank, and each one has a datapoint that measures the temperature of the cooling tank. The asset names for the cooling tanks must be different, e.g. TankA and TankB, but each can have a datapoint called temperature.
There are three options supported within the plugin for generation of identifiers
Use the asset name as the point identifier
This can only be used if there is a single datapoint for each asset, as if there are multiple datapoints within an asset they would share the same point within eDNA and would not be distinguishable.
Use the datapoint name as the point identifier
In this case assets can have multiple datapoints, as the datapoint names are unique within an asset. However if you have multiple assets and those assets have datapoints with the same name in two or more assets, this method will also result in datapoints sharing the same point within eDNA.
Combine the asset name and datapoint name to create the identifier.
This is the safest option, as it will also create unique identifiers, but they are longer and may be difficult to arrange to create names that exactly match the names of predefined points in eDNA. Identifiers will get truncated to the limits of eDNA, for example if you are using short identifiers only the first 8 characters are significant. A long identifier is limited to 60 characters and an extended identifier is limited to 128 characters.
If the plugin detects that the constructed identifier being used to insert the point into eDNA is too long and will be truncated by eDNA then a warning will be written to the error log. This will not prevent the point being written to eDNA, as it is perfectly acceptable to supply eDNA with an over length identifier, however to avoid sharing of data point within eDNA the truncated identifier must be unique. To prevent the error log being overwhelmed with these warnings they will be written once per execution of the north service or task that is forwarding data to eDNA.
Matching Predefined Points¶
If using the mode of operation in which you wish to put data in points in eDNA that have been previously created it is probably best to use the datapoint name as the identifier. In the ingest plugins you should setup the datapoint names to match the point names in eDNA. For example if using the MODBUS plugin to read data then set the datapoint name in the MODBUS map to be the eDNA point name.
If this can not be done, or you do not control the datapoint naming, then a filter, such as the asset filter, can be used to change the names of the datapoints before they are processed by the eDNA plugin. This can either be done in the pipeline in the south service, in which case the names are changed for all north services, or in the north service pipeline if you only wish the name change to occur in the eDNA pipeline.
Using the asset filter to set the datapoint name, or asset name, to match the eDNA point identifier is a simple way to match the point names, but has the disadvantage that the eDNA point names will also be used when sending the data to any other destinations if applied in the south service pipeline. To avoid this add the asset filter to the north service or use hints to control the eDNA point names.
The eDNA Hint can be added to the pipeline to explicitly set the ID to use for a point. This allows each of the short, long and extended id value to be given explicitly as well as defining a description, extended description, units and history retention configuration that will be used if FLIR Bridge creates the eDNA points. The advantage of uses hints over merely matching the asset names or datapoint names to the eDNA point names is that we can set all three ID values and also other attributes of the points. These are only used however if FLIR Bridge is creating the eDNA points, either method work equally well if the points have been pre-created in eDNA and FLIR Bridge is not creating the eDNA points.
If the identifier generated by FLIR Bridge does not match the name of the point within eDNA and point creation is turned off in the plugin configuration, then the data will be lost. This will be written to the log file, however not every data loss will be recorded, it will only be written again every 15 minutes. This prevents the log from becoming flooded with errors when data points are missing within eDNA.