Regex Filter¶
The flir-filter-regex plugin is a simple filter that allows the user to find asset name, datapoint name or values in string type datapoints and replace them with new values. It uses regular expressions to match and replaces these values with replacement values. All or part of the matching regular expression may be used in the replacement
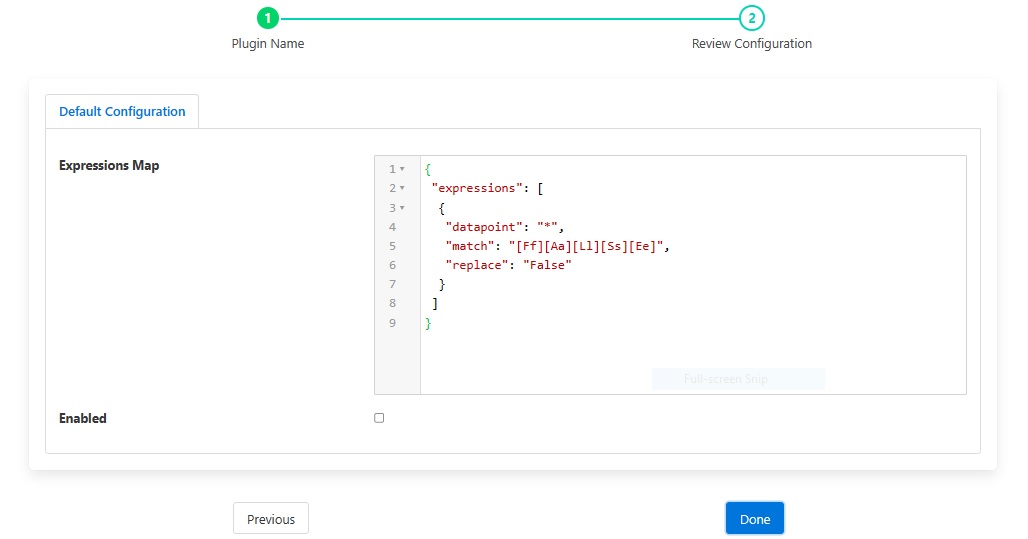
A set of find and replace expressions are given in an expression map, along with the optional asset and datapoint names to which this are applied.
When adding filter a configuration page for the filter will be shown as below;
|
Scope: The scope with which the filter will operate. Three scopes are supported:
String Datapoints: Value of datapoints of string type can be modified
Asset Name: Asset name can be modified
Datapoint Name: Datapoint name can be modified
Expressions Map: The set of regular expressions to match and replace. Each element in the array contains up to four items. The are:
asset: Apply filter to only specified asset if present, otherwise apply to all the assets.
datapoint: Apply filter to only specified datapoint if present, otherwise apply to all the datapoints.
match: A regular expression to match with the datapoint value, asset name or datapoint name. This item is mandatory and must be included in each expression in the JSON array.
replace: A new value as a replacement, if the regular expression matches. This item is also mandatory for every element of the array.
Regular Expressions¶
The filter supports the standard Linux regular expression syntax
Expression |
Description |
|---|---|
. |
Matches any character |
[] |
Matches any of the characters enclosed in the brackets |
[a-z] |
Matches any characters in the range between the two given |
[:class] |
Matches any character in the character class given. Valid character classes are alnum, digit, punct, alpha, graph, space, blank, lower, upper, cntrol, print and xdigit. |
* |
Matches zero or more occurrences of the previous item |
+ |
Matches one or more occurrence of the previous item |
? |
Matches zero or one occurrence of the previous item |
{i, j} |
Matches between i and j occurrences of the previous item. Where i and j are integers. |
^ |
Matches the start of the string |
$ |
Matches the end of the string |
(expression) |
Marks the enclosed expression as a single item in the expression and also makes it available for substitution into the replacement string |
! |
Marks a branch in a regular expression, the pattern may match either the expression to the left or right |
Examples¶
To match a word, defined as one or more letters, we can use the regular expression
[A-Za-z]+
Or alternatively we can use the character class form of this
[:alpha]+
If we wanted to match capitalised words only then we could use
[A-Z][a-z]*
In the above case we only allow the initial letter of the word to be capitalised.
If we wanted to match only words starting with an a or b character there are a number of ways we could do this
[ab][a-z]*
or
a|b[a-z]*
If we wanted to match a word that starts with un or re then we can use the branch operator with brackets
(un)|(re)[a-z]+
If we wanted to match the words table and tables we can use the ? operator
tables?
The above are use a few examples of regular expressions that can be used, but serve to illustrate the most used operators that are available.
Replacement Text¶
The replacement text can be a simple value or can reference portions of the regular expression that is matched. To use a portion of the matching regular expression in the replacement text surround the portion you wish to use in brackets. For example, to match any characters and replace the text with the matching characters but add a suffix of “measured” the following can be used;
"match" : "(.*)",
"replace" : "$1measured"
Subsections of the matching text can be used, for example to swap two words;
"match" : "([A-Za-z]+) ([A-Za-z]+)",
"replace" : "$2 $1"