PI Server South Plugin¶
The AVEVA PI Core suite of products represents software systems deployed at a customer site. Together, these systems collect, store, enhance, organize, and visualize real-time data streams. The heart of the PI Core portfolio is the PI Server which consists of the PI Data Archive and the PI Asset Framework (AF). This South plugin reads PI Server data by exception which means that the plugin is notified of data changes in PI. This guarantees that data changes will not be missed. Because of this, the plugin does not need to poll the PI Server for current data values.
The South service to collect PI Server data is created in the same way as any other south service in FLIR Bridge.
Use the South option in the left hand menu bar to display a list of your South services
Click on the + add icon at the top right of the page
Select the piserver plugin from the list
Enter a name for your south service
Click on Next to configure the PI Server plugin
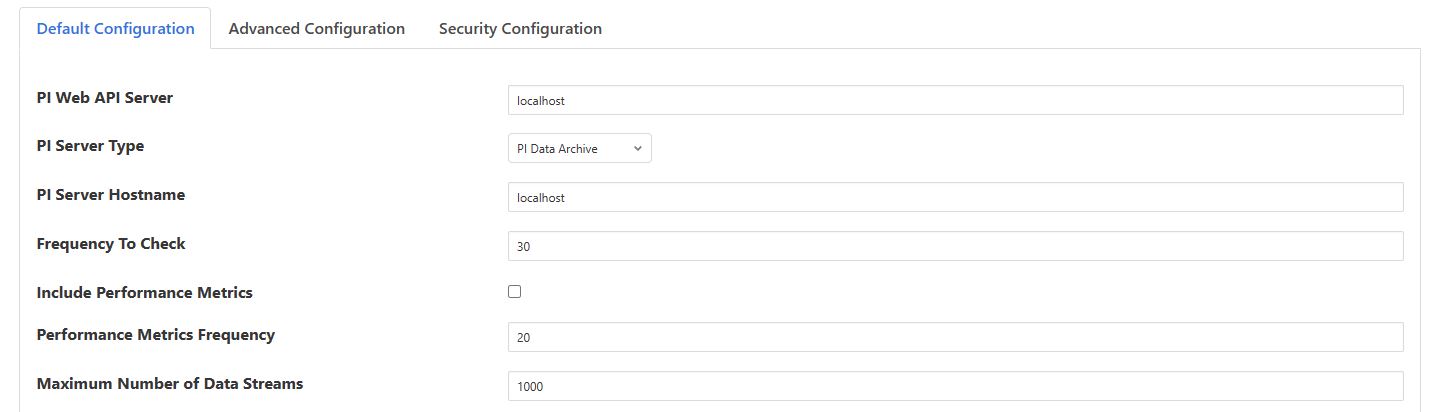
The configuration parameters that can be set on this page are:
- Basic Information:
PI Web API Server: The hostname or address of the PI Web API server. This is often the same address as the PI Server.
PI Server Type: A drop-down to select the PI Server type. Choices are: PI Data Archive and PI Asset Framework.
PI Server: The hostname of the PI Server. This hostname must be known to the system running the PI Web API Server. To find valid PI Data Archive server names, use a browser to run the PI Web API query https://myhost/piwebapi/dataservers. To find valid PI Asset Framework server names, run the PI Web API query https://myhost/piwebapi/assetservers.
Frequency To Check: Choose how frequently to check the PI Server for data updates, in seconds.
Include Performance Metrics: If true, periodically produce a separate Reading with plugin performance metrics.
Performance Metrics Frequency: Rate at which to generate performance metrics, as multiples of Frequency.
Maximum Number of Data Streams: The Query Parameters configuration may result in the selection of an overly large number of PI Data Archive tags or Asset Framework Attributes. The Maximum Number of Data Streams configuration is a limit to the number of data streams loaded. If this number of data streams is reached, the PI Server South plugin will stop loading further data streams and log a warning that the number has been limited. This parameter can serve as a check during development of your Query Parameters. The default is 1000 data streams. If this parameter is set to zero, there is no limit to the number of data streams loaded.
|
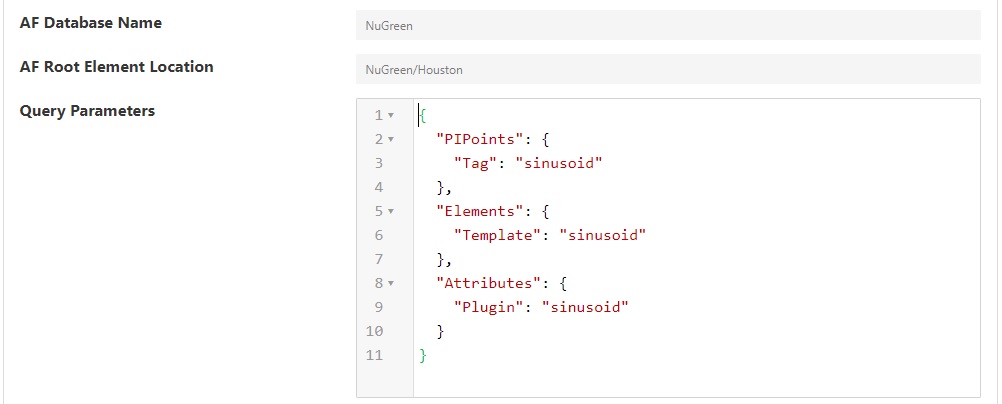
- For Asset Framework configurations:
AF Database Name: Name of an AF Database hosted by the selected PI Asset Framework server.
AF Root Element Location: Top level of the AF hierarchy to search for AF Attributes.
Query Parameters: A JSON document with filters for querying the PI Data Archive and PI Asset Framework. See the Query Parameters section below.
|
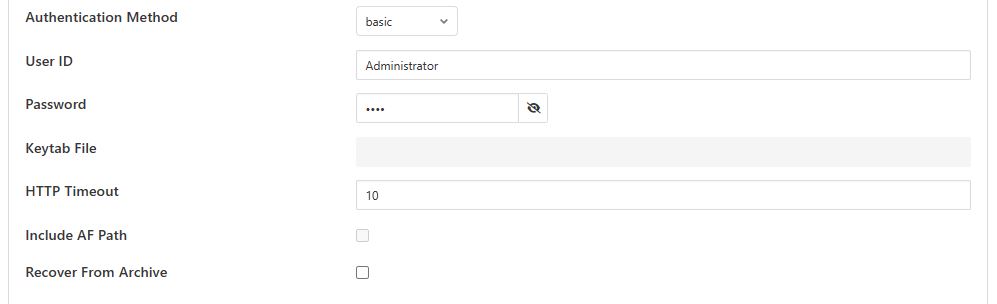
- PI Web API authentication
PI Web API Authentication Method: A drop-down with the authentication method to be used: Anonymous, Basic or Kerberos. Anonymous equates to no authentication. Basic authentication requires a username and password. Kerberos allows integration with your single sign-on environment.
PI Web API User ID: For Basic authentication, the username to authenticate with the PI Web API.
PI Web API Password: For Basic authentication, the user’s password.
PI Web API Kerberos keytab file: The Kerberos keytab file used to authenticate.
- Connection management (These should only be changed with guidance from Technical Support):
HTTP Timeout: Number of seconds to wait before FLIR Bridge will time out an HTTP request.
- AF Path:
Include AF Path: Add AF Path as a datapoint named AFPath in the readings. This option is valid only if PI Server Type is PI Asset Framework. If this option is not selected, the asset name for a reading will be the full path of the AF Attribute without the AF Attribute name itself. If this option is selected, asset name will be only the AF Element name that owns the AF Attribute. In this case, the AF path can be obtained only from AFPath datapoint. The AFPath datapoint name always begins with a leading forward slash (“/”).
- Recover from Archive:
If Recover from Archive is checked, the PI Server South plugin will fill the time gap in Stream Updates by reading data values from the PI Server archive. This checkbox is not checked by default. The section Recovery of Data from the PI Data Archive has more details on this feature.
Query Parameters¶
The Query Parameters configuration is a JSON document that specifies filters for finding PI Points or AF Attributes of interest. Query Parameters have three sections:
PIPoints : Used when PI Server Type is PI Data Archive
Elements : Used when PI Server Type is AF Asset Framework
Attributes : Used when PI Server Type is AF Asset Framework
Syntax can be found in the page Search Query Syntax. You can also create configurations which are arrays of queries. See the sub-section Array of Queries below.
PI Data Archive Queries¶
PI Points can be searched by any PI Point Attribute value. The common choices are:
Tag
Name
Descriptor
PointType
PointSource
ChangeDate
DigitalSet
Engineering Units
To Search by more than one condition you need to use the operator JoinWith. For example:
{ "PIPoints": { "Tag": "sinusoid", "JoinWith": "AND", "PointType": "Int32", "JoinWith": "OR", "EngUnits":"STATE" } }
If JoinWith is not specified, the AND operator is assumed.
By default, the key/value pair uses the equal operator to find PIPoints.
To find PIPoints by inequality, add the inequality operator (“<>”) to the key/value pair.
For example, "Tag":"<>sinusoid".
Note that no space is allowed between the operator “<>” and the value.
PI Asset Framework Queries¶
PI Asset Framework queries consist of an Attributes JSON object and an optional Elements JSON object.
Attributes can be searched by any Attribute value. The common choices are:
Name
Template
PlugIn
Type
The PlugIn query parameter can be used to find Attributes with specific Data References.
For example, you can find AF Attributes mapped to PI Points with the filter "PlugIn":"PI Point":
{ "Attributes": { "Name": "Temperature", "PlugIn": "PI Point" } }
To filter Elements that own the Attributes of interest, include an Elements JSON object. Filters that can be used inside the Elements object are:
Root
Name
Template
Category
CreationDate
For example:
{ "Elements": { "Root": "NuGreen", "Category": "Locations" } }
Key/Value filters inside the Elements object support only equality. You cannot use the inequality operator (“<>”).
Array of Queries¶
You can define multiple queries in the same configuration by introducing the Queries array. The members of this array are the PIPoints, Attributes and Elements query objects defined above. For example, to find PI Points with two different tag masks:
{ "Queries":[ { "PIPoints":{ "Tag":"sinu*" } }, { "PIPoints":{ "Tag":"cd*" } } ] }
The PI Server South plugin will process Stream Updates from both sets of tag masks. There is no limit to the number of queries that can appear in the Queries array. It is harmless if two or more configurations generate the same or an overlapping set of data streams.
Specifying multiple PI Asset Framework queries is similar. For example, to find the Quality Attribute from all Locations and the Fuel Gas Flow from all Boilers, specify the query array:
{ "Queries":[ { "Elements":{ "Category":"Locations" }, "Attributes":{ "Name":"Quality", "PlugIn":"PI Point" } }, { "Elements":{ "Template":"Boiler" }, "Attributes":{ "Name":"Fuel Gas Flow", "PlugIn":"PI Point" } } ] }
Principles of Operation¶
The PI Server South plugin uses the Stream Updates feature of the PI Web API to retrieve data updates from the PI Server. For PI Data Archive points and AF Attributes mapped to the PI Point Data Reference, this means data values are queued by the PI Data Archive’s Update Manager. The data values remain in the Update Manager’s queue until the PI Server South plugin requests them. The Frequency To Check configuration parameter determines how often the PI Server South plugin will check the queue for data updates.
Data value updates retrieved using the Stream Updates mechanism are labelled with a code indicating whether the data value is new (that is, later than the snapshot), inserted into history, updating a value in history, or deleted. All of these codes will cause a new Reading to be sent to FogLamp except Delete.
Recovery of Data from the PI Data Archive¶
If a PI Server South plugin instance has been down for more than 5 minutes, PI Data Archive’s Update Manager will stop queuing data updates for the plugin instance. When the plugin restarts, it will register for Stream Updates again and will process only new data updates that are received by the PI Server. There will, however, be a gap in the stream of data updates sent to FogLamp.
Archive recovery at plugin startup is common. Recovery will also start automatically if the PI Server recovers from a fault such as overflow of the PI Data Archive’s Update Manager queue.
The plugin will send data to FogLamp in time order. Any data values read from the archive will be sent to FogLamp first. Meanwhile, the plugin will cache new Stream Updates until archive recovery is complete.
If a data stream is registered by the plugin for the first time, there will be no archive recovery. The plugin must have a starting point which is the time of the last data update read from Stream Updates. The latest timestamp is persisted for every data stream by the plugin when it shuts down.
If the plugin has been down for a long time (that is, days or weeks), archive recovery could take a long time. It may be advisable in this case to turn off the Recover from Archive feature before starting the plugin. The feature can be re-enabled after some Stream Updates have been processed.
When archive recovery for a data stream begins, the PI Server South plugin will move it to an internal structure called the Archive Recovery cache. Changes in the number of data streams in the cache will be logged so that system administrators are aware of the number of data streams in recovery. When the number of data streams in the cache changes, either up or down, this message is logged:
WARNING: Archive Recovery cache size changed from 0 to 90
When archive recovery is complete, the data stream is removed from the Archive Recovery cache and normal operation will resume.
There is a subtle difference between data read using Stream Updates and data read from the archive. Stream Updates will deliver all data updates that are sent to the PI Server. Depending on the PI Server’s exception and compression specs, not all Stream Updates may be archived. When recovering data values from the archive, data values that were never sent to the PI Data Archive cannot be recovered.
In the PI Server, Stream Updates are implemented in the PI Data Archive Update Manager. This subsystem supports PI Data Archive points and AF Attributes mapped to PI points using the PI Point Data Reference. The PI Server South plugin also supports other data references as long as they support new data values by exception and historical data retrieval.
Monitoring the Update Manager Queue¶
The status of the PI Data Archive Update Manager queue can be monitored using the PI System Manager Tools (PI SMT) application which can be obtained from AVEVA. In the Servers section in the upper left corner, connect to the system running the PI Data Archive. In the left-side menu pane, open Operation and then Update Manager. In the Server drop-down at the top of the screen, choose the PI Data Archive system; this selection is not made by default.
|
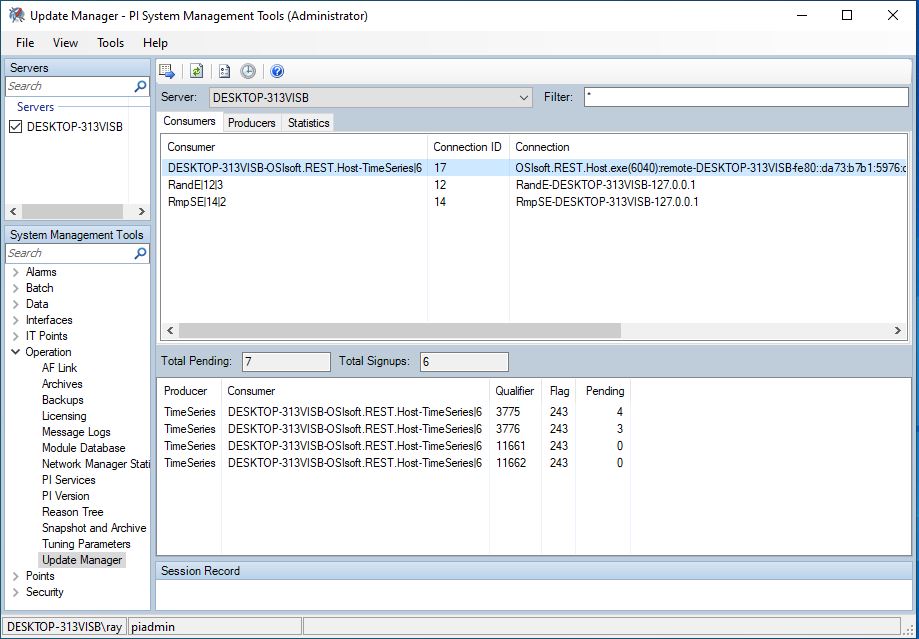
In the Consumer list in the upper pane, you will see the PI Web API server name followed by OSIsoft.REST.Host-TimeSeries and a number. This represents the request for data updates registered by the PI Web API. In the lower pane, you will see entries for the individual TimeSeries items. The number to watch is the Total Pending in the lower pane. This normally climbs and then resets to a low number when the PI Server South plugin has retrieved data updates.
Lower Frequency To Check numbers mean the Update Manager queue will be checked more often resulting in a more timely retrieval of data updates. The Frequency To Check value should be adjusted so that the maximum Total Pending number remains below 10,000. If the Total Pending number climbs above 50,000, the Update Manager queue will overflow. If this happens, the PI Web API’s Consumer will be closed by the PI Data Archive and no further data values will be queued. The PI Data Archive will also close the PI Web API’s Consumer if no data updates have been requested for 5 minutes.
Note
Due to a known problem in the PI Web API, a REST client will not be notified if the data update queue overflows. There is also no notification to a REST client if the PI Server is restarted. In both of these cases, the PI Server South plugin will continue to request data updates but no error will be reported and no data will be returned. The PI Server South plugin works around this by monitoring the flow of data updates. If no data updates are retrieved for 4 minutes, the PI Server South plugin will re-register its data streams.
Meta Data Changes in the PI Server¶
It may occur that the PI Server administrator makes changes to PI Server meta data while PI Server South is running. This means changes in AF Attribute properties for AF Database configurations, and changes in PI Point attributes for PI Data Archive configurations.
Edits¶
For changes in AF Attribute properties, PI Server South is notified of any edits that affect the retrieval of data updates. This plugin will respond to this by re-registering for stream updates with PI Web API if necessary. PI Server South should continue to retrieve data updates without interruption unless the change causes data flow to stop. An example of this is removing the Data Reference associated with an AF Attribute.
For changes in PI Point attributes, PI Server South is not notified. If you are aware of PI Point attribute edits that will affect your configuration, restart your PI Server South instance. The plugin saves its context during the restart and will continue processing data updates without loss of data.
Deletions¶
PI Server South is not notified of the deletion of a PI Point or AF Attribute. To account for this, the plugin will periodically check the presence of its PI Points or AF Attributes if there have been no data updates in 5 minutes. If any PI Points or AF Attributes are determined to be missing, it will stop attempting to read data updates from them.
Creations¶
PI Server South cannot determine if new PI Points or AF Attributes are created that will match your Query Parameters. If this occurs, restart your PI Server South instance. The plugin saves its context during the restart and will continue processing data updates without loss of data.
Performance Metrics¶
If the Include Performance Metrics configuration setting is checked, the PI Server South plugin will periodically generate a Reading with metrics to show the performance of data update retrieval from the PI Web API. The Performance Metrics Frequency configuration setting determines the time period. The setting is multiples of Frequency To Check. For example, if the value is 4 then every 4th retrieval of data updates will be accompanied by a performance metrics Reading. If the Frequency To Check is 30 seconds, then performance metrics will be generated every 2 minutes (30 seconds times 4).
Performance metrics appear in a Reading that is sent to FLIR Bridge. The asset name of the Reading is Metrics. followed by the name of your service. The Reading has 3 Datapoints:
Datapoint Name |
Description |
|---|---|
NumCalls |
Number of PI Web API calls issued to retrieve data updates |
NumValues |
The total number of data values retrieved using the PI Web API |
TotalTime |
Total elapsed time of all PI Web API calls, in seconds |
The Datapoints represent accumulated values since the last performance metrics Reading.